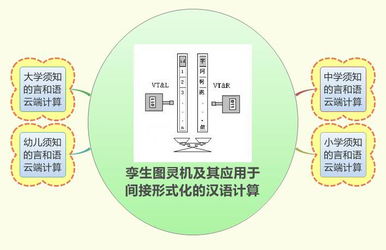
Hadoop是一個開源的分布式計算框架,由Apache軟件基金會開發和維護,旨在高效處理大規模數據集。它基于Google的MapReduce和Google File System(GFS)論文設計,廣泛應用于大數據分析和軟件開發領域。本文將從Hadoop的核心組件、架構原理、優勢與挑戰,以及在軟件開發中的應用場景進行詳細分析。
Hadoop核心組件
Hadoop生態系統主要由兩個核心部分組成:Hadoop Distributed File System(HDFS)和MapReduce。
- HDFS(Hadoop分布式文件系統):這是一個高度容錯的分布式存儲系統,設計用于運行在廉價硬件上。它將數據分割成塊(通常為128MB或256MB),并復制到多個節點上,確保數據冗余和可靠性。HDFS采用主從架構,包括NameNode(管理文件系統元數據)和DataNode(存儲實際數據)。在軟件開發中,HDFS提供了一個可擴展的存儲基礎,支持海量數據的讀寫操作。
- MapReduce:這是一個編程模型,用于并行處理大規模數據集。它將計算任務分為兩個階段:Map和Reduce。Map階段對輸入數據進行過濾和排序,生成中間鍵值對;Reduce階段則對中間結果進行聚合。這種模型簡化了分布式編程,使開發人員能夠專注于業務邏輯,而無需處理底層并行化細節。
Hadoop生態系統還包括其他重要工具,如YARN(資源管理器)、Hive(數據倉庫工具)、Pig(數據流語言)和HBase(NoSQL數據庫),這些工具擴展了Hadoop的功能,使其在軟件開發中更加靈活。
Hadoop架構原理
Hadoop采用分布式架構,運行在集群環境中。集群由多個節點組成,包括主節點(如NameNode和ResourceManager)和從節點(如DataNode和NodeManager)。數據被分割存儲在多臺機器上,計算任務并行執行,從而顯著提高處理速度。HDFS通過數據復制(默認3份)確保高可用性,而MapReduce通過任務調度和容錯機制自動處理節點故障。這種架構使Hadoop能夠水平擴展,即通過增加節點來提升性能,非常適合處理PB級別的數據。
Hadoop的優勢與挑戰
優勢:
- 可擴展性:Hadoop可以輕松擴展到數千個節點,處理海量數據。
- 成本效益:它運行在廉價硬件上,降低了基礎設施成本。
- 容錯性:自動處理節點故障,確保數據不丟失。
- 靈活性:支持結構化、半結構化和非結構化數據,適用于多種應用場景。
挑戰:
- 復雜性:部署和維護Hadoop集群需要專業知識,增加了開發難度。
- 實時性不足:MapReduce批處理模型不適合實時分析,需要結合其他工具如Spark。
- 安全風險:早期版本的安全機制較弱,需通過Kerberos等工具加強。
Hadoop在軟件開發中的應用
在軟件開發中,Hadoop被廣泛應用于大數據處理、日志分析、機器學習等領域。例如:
- 數據倉庫構建:使用Hive或Pig,企業可以構建ETL(提取、轉換、加載)管道,處理交易數據并生成報告。
- 推薦系統:電商平臺利用Hadoop分析用戶行為數據,實現個性化推薦。
- 日志處理:互聯網公司使用MapReduce處理服務器日志,識別性能瓶頸和安全威脅。
Hadoop框架為軟件開發提供了強大的分布式計算能力,盡管存在一些挑戰,但通過生態系統工具的補充,它已成為大數據時代不可或缺的技術。開發人員應結合項目需求,合理選擇Hadoop組件,以優化數據處理流程。